前言
介绍监督微调训练器。
监督式微调(简称SFT)是RLHF(人类反馈强化学习)中的关键步骤。在TRL(Transformers Reinforcement Learning)中,我们提供了一个易于使用的API,您可以使用几行代码在您的数据集上创建SFT模型并进行训练。
查看一个完整的灵活示例,位于 examples/scripts/sft.py。在示例 examples/scripts/vsft_llava.py 中也包含了对于视觉语言模型的实验性支持。
src link: https://huggingface.co/docs/trl/sft_trainer
Colab: https://colab.research.google.com/
Operating System: Ubuntu 22.04.4 LTS
参考文档
快速入门
如果您有一个托管在 🤗 Hub 上的数据集,您可以使用TRL中的SFTTrainer轻松地对您的SFT模型进行微调。假设您的数据集是imdb,您想要预测的文本位于数据集的text字段中,并且您想要微调facebook/opt-350m模型。以下代码片段将为您处理所有数据预处理和训练工作:
from datasets import load_dataset
from trl import SFTConfig, SFTTrainer
dataset = load_dataset("stanfordnlp/imdb", split="train")
sft_config = SFTConfig(
dataset_text_field="text",
per_device_train_batch_size=4,
max_seq_length=512,
output_dir="/tmp",
)
trainer = SFTTrainer(
"facebook/opt-350m",
train_dataset=dataset,
args=sft_config,
)
trainer.train()确保为 max_seq_length 传递正确的值,因为默认值将被设置为 min(tokenizer.model_max_length, 1024)。
您还可以在训练器外部构建一个模型,然后按如下方式传递它:
from transformers import AutoModelForCausalLM
from datasets import load_dataset
from trl import SFTConfig, SFTTrainer
dataset = load_dataset("stanfordnlp/imdb", split="train")
model = AutoModelForCausalLM.from_pretrained("facebook/opt-350m")
sft_config = SFTConfig(
dataset_text_field="text",
per_device_train_batch_size=4,
max_seq_length=512,
output_dir="/tmp"
)
trainer = SFTTrainer(
model,
train_dataset=dataset,
args=sft_config,
)
trainer.train()上述代码片段将使用SFTConfig类中的默认训练参数。如果您想要修改这些默认值,可以将您的修改传递给SFTConfig构造函数,并通过args参数将它们传递给训练器。
高级用法
Train on completions only
您可以使用DataCollatorForCompletionOnlyLM来仅在生成的提示上训练您的模型。请注意,这种情况仅在packing=False时有效。要为指令数据实例化该整理器,请传递一个响应模板和分词器。以下是如何仅在CodeAlpaca数据集上对opt-350m进行仅完成任务的微调的示例:
from transformers import AutoModelForCausalLM, AutoTokenizer
from datasets import load_dataset
from trl import SFTConfig, SFTTrainer, DataCollatorForCompletionOnlyLM
dataset = load_dataset("lucasmccabe-lmi/CodeAlpaca-20k", split="train")
model = AutoModelForCausalLM.from_pretrained("facebook/opt-350m")
tokenizer = AutoTokenizer.from_pretrained("facebook/opt-350m")
def formatting_prompts_func(example):
output_texts = []
for i in range(len(example['instruction'])):
text = f"### Question: {example['instruction'][i]}\n ### Answer: {example['output'][i]}"
output_texts.append(text)
return output_texts
response_template = " ### Answer:"
collator = DataCollatorForCompletionOnlyLM(response_template, tokenizer=tokenizer)
trainer = SFTTrainer(
model,
train_dataset=dataset,
args=SFTConfig(
per_device_train_batch_size=16,
output_dir="/tmp"
),
formatting_func=formatting_prompts_func,
data_collator=collator,
)
trainer.train()要为助手风格对话数据实例化该整理器,请传递一个响应模板、一个指令模板和分词器。以下是如何仅在Open Assistant Guanaco数据集上对opt-350m进行仅助手完成任务微调的示例:
from transformers import AutoModelForCausalLM, AutoTokenizer
from datasets import load_dataset
from trl import SFTConfig, SFTTrainer, DataCollatorForCompletionOnlyLM
dataset = load_dataset("timdettmers/openassistant-guanaco", split="train")
model = AutoModelForCausalLM.from_pretrained("facebook/opt-350m")
tokenizer = AutoTokenizer.from_pretrained("facebook/opt-350m")
instruction_template = "### Human:"
response_template = "### Assistant:"
collator = DataCollatorForCompletionOnlyLM(instruction_template=instruction_template, response_template=response_template, tokenizer=tokenizer, mlm=False)
trainer = SFTTrainer(
model,
args=SFTConfig(
dataset_text_field = "text",
per_device_train_batch_size=4,
max_seq_length=512,
output_dir="/tmp",
),
train_dataset=dataset,
data_collator=collator,
)
trainer.train()确保您有一个pad_token_id,它与eos_token_id不同,这样可以避免模型在生成过程中不正确地预测EOS(句子结束)标记。
Using token_ids directly for response_template
一些分词器,如Llama 2(meta-llama/Llama-2-XXb-hf),根据是否有上下文,会以不同的方式对序列进行分词。例如:
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("meta-llama/Llama-2-7b-hf")
def print_tokens_with_ids(txt):
tokens = tokenizer.tokenize(txt, add_special_tokens=False)
token_ids = tokenizer.encode(txt, add_special_tokens=False)
print(list(zip(tokens, token_ids)))
prompt = """### User: Hello\n\n### Assistant: Hi, how can I help you?"""
print_tokens_with_ids(prompt) # [..., ('▁Hello', 15043), ('<0x0A>', 13), ('<0x0A>', 13), ('##', 2277), ('#', 29937), ('▁Ass', 4007), ('istant', 22137), (':', 29901), ...]
response_template = "### Assistant:"
print_tokens_with_ids(response_template) # [('▁###', 835), ('▁Ass', 4007), ('istant', 22137), (':', 29901)]在这种情况下,由于响应模板中缺乏上下文,相同的字符串(”### Assistant:”)会被分词器以不同的方式处理:
- Text (with context): [2277, 29937, 4007, 22137, 29901]
- response_template (without context): [835, 4007, 22137, 29901]
这将导致当DataCollatorForCompletionOnlyLM在数据集示例文本中找不到响应模板时发生错误:
RuntimeError: Could not find response key [835, 4007, 22137, 29901] in token IDs tensor([ 1, 835, ...])为了解决这个问题,您可以使用与数据集中相同的上下文对响应模板进行分词,根据需要对其进行截断,并将token_ids直接传递给DataCollatorForCompletionOnlyLM类的response_template参数。例如:
response_template_with_context = "\n### Assistant:" # We added context here: "\n". This is enough for this tokenizer
response_template_ids = tokenizer.encode(response_template_with_context, add_special_tokens=False)[2:] # Now we have it like in the dataset texts: `[2277, 29937, 4007, 22137, 29901]`
data_collator = DataCollatorForCompletionOnlyLM(response_template_ids, tokenizer=tokenizer)Add Special Tokens for Chat Format
在语言模型中添加特殊令牌对于训练聊天模型至关重要。这些令牌被添加到对话中的不同角色之间,例如用户、助手和系统,帮助模型识别对话的结构和流程。这种设置对于使模型能够在聊天环境中生成连贯且上下文适当的响应至关重要。trl中的setup_chat_format()函数可以轻松地为对话AI任务设置模型和分词器。这个函数执行以下操作:
- 向分词器添加特殊令牌,例如<|im_start|>和<|im_end|>,以指示对话的开始和结束。
- 调整模型的嵌入层大小,以适应新的令牌。
- 设置分词器的chat_template,该模板用于将输入数据格式化为类似聊天的格式。默认值是OpenAI的chatml。
- 可选地,您可以传递resize_to_multiple_of参数,将嵌入层的大小调整为resize_to_multiple_of参数的倍数,例如64。如果您希望将来支持更多格式,请在trl上打开一个GitHub问题。
from transformers import AutoModelForCausalLM, AutoTokenizer
from trl import setup_chat_format
# Load model and tokenizer
model = AutoModelForCausalLM.from_pretrained("facebook/opt-350m")
tokenizer = AutoTokenizer.from_pretrained("facebook/opt-350m")
# Set up the chat format with default 'chatml' format
model, tokenizer = setup_chat_format(model, tokenizer)现在我们的模型和分词器已经设置好了,我们可以开始在对话数据集上微调我们的模型。以下是数据集如何格式化以进行微调的一个例子。
Dataset格式支持
SFTTrainer 支持流行的数据集格式。这允许您无需任何预处理,直接将数据集传递给训练器。以下格式均受支持:
- conversational format:
{"messages": [{"role": "system", "content": "You are helpful"}, {"role": "user", "content": "What's the capital of France?"}, {"role": "assistant", "content": "..."}]}
{"messages": [{"role": "system", "content": "You are helpful"}, {"role": "user", "content": "Who wrote 'Romeo and Juliet'?"}, {"role": "assistant", "content": "..."}]}
{"messages": [{"role": "system", "content": "You are helpful"}, {"role": "user", "content": "How far is the Moon from Earth?"}, {"role": "assistant", "content": "..."}]}- instruction format:
{"prompt": "<prompt text>", "completion": "<ideal generated text>"}
{"prompt": "<prompt text>", "completion": "<ideal generated text>"}
{"prompt": "<prompt text>", "completion": "<ideal generated text>"}如果您的数据集使用上述格式之一,您可以无需预处理直接将其传递给训练器。SFTTrainer 将使用模型分词器的定义格式,通过 apply_chat_template 方法为您格式化数据集。
from datasets import load_dataset
from trl import SFTConfig, SFTTrainer
...
# load jsonl dataset
dataset = load_dataset("json", data_files="path/to/dataset.jsonl", split="train")
# load dataset from the HuggingFace Hub
dataset = load_dataset("philschmid/dolly-15k-oai-style", split="train")
...
sft_config = SFTConfig(packing=True)
trainer = SFTTrainer(
"facebook/opt-350m",
args=sft_config,
train_dataset=dataset,
)如果数据集不是上述格式之一,您可以选择预处理数据集以匹配所需的格式,或者向 SFTTrainer 传递一个格式化函数,让它为您完成这项工作。让我们来看一看。
格式化您的输入提示
对于指令微调,数据集中通常包含两列:一列用于提示(prompt),另一列用于响应(response)。这允许人们按照Stanford-Alpaca项目的方式格式化示例,如下所示:
Below is an instruction ...
### Instruction
{prompt}
### Response:
{completion}让我们假设您的数据集有两个字段,分别是问题和答案。因此,您可以运行以下命令:
def formatting_prompts_func(example):
output_texts = []
for i in range(len(example['question'])):
text = f"### Question: {example['question'][i]}\n ### Answer: {example['answer'][i]}"
output_texts.append(text)
return output_texts
trainer = SFTTrainer(
model,
args=sft_config,
train_dataset=dataset,
formatting_func=formatting_prompts_func,
)
trainer.train()为了正确格式化您的输入,请确保通过遍历所有示例并返回处理后的文本列表来进行处理。您可以在这里查看如何在alpaca数据集上使用SFTTrainer的完整示例。
Packing dataset ( ConstantLengthDataset )
SFTTrainer 支持示例打包,其中多个简短的示例被打包到同一个输入序列中,以提高训练效率。这是通过 ConstantLengthDataset 实用程序类完成的,该类从一系列示例中返回固定长度的令牌块。要启用这个数据集类的使用,只需将 packing=True 传递给 SFTConfig 构造函数即可。
sft_config = SFTConfig(packing=True, dataset_text_field="text",)
trainer = SFTTrainer(
"facebook/opt-350m",
train_dataset=dataset,
args=sft_config
)
trainer.train()请注意,如果您使用打包的数据集,并且在训练参数中传递了 max_steps,您可能会根据您配置打包数据集和训练协议的方式,训练模型超过几个周期。请务必双倍检查您知道自己在做什么,并且理解这些操作。如果您不希望对 eval_dataset 进行打包,可以在 SFTConfig 初始化方法中传递 eval_packing=False。
Customize your prompts using packed dataset
如果您的数据集有多个字段需要合并,例如数据集有问题和答案字段,而您想要将它们结合起来,您可以向训练器传递一个格式化函数来处理这个问题。例如:
def formatting_func(example):
text = f"### Question: {example['question']}\n ### Answer: {example['answer']}"
return text
sft_config = SFTConfig(packing=True)
trainer = SFTTrainer(
"facebook/opt-350m",
train_dataset=dataset,
args=sft_config,
formatting_func=formatting_func
)
trainer.train()您还可以通过直接向 SFTConfig 构造函数传递参数来进一步自定义 ConstantLengthDataset。请参考该类的签名以获取更多信息。
对预训练模型的控制
您可以直接将from_pretrained()方法的kwargs传递给SFTConfig。例如,如果您想以不同的精度加载模型,类似于:
model = AutoModelForCausalLM.from_pretrained("facebook/opt-350m", torch_dtype=torch.bfloat16)
...
sft_config = SFTConfig(
model_init_kwargs={
"torch_dtype": "bfloat16",
},
output_dir="/tmp",
)
trainer = SFTTrainer(
"facebook/opt-350m",
train_dataset=dataset,
args=sft_config,
)
trainer.train()请注意,from_pretrained()的所有关键字参数都是支持的。
Training adapters
我们也支持与🤗 PEFT库的紧密集成,以便任何用户都可以方便地训练适配器并在Hub上分享,而不是训练整个模型。
from datasets import load_dataset
from trl import SFTConfig, SFTTrainer
from peft import LoraConfig
dataset = load_dataset("stanfordnlp/imdb", split="train")
peft_config = LoraConfig(
r=16,
lora_alpha=32,
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM",
)
trainer = SFTTrainer(
"EleutherAI/gpt-neo-125m",
train_dataset=dataset,
args=SFTConfig(
dataset_text_field="text",
per_device_train_batch_size=4,
max_seq_length=512,
output_dir="/tmp"
),
peft_config=peft_config
)
trainer.train()您还可以继续训练您的PeftModel。为此,首先在SFTTrainer之外加载一个PeftModel,并将其直接传递给训练器,而不需要传递peft_config参数。
Training adapters with base 8 bit models
为此,您需要首先在Trainer外部加载您的8位模型,并将一个PeftConfig传递给训练器。例如:
peft_config = LoraConfig(
r=16,
lora_alpha=32,
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM",
)
model = AutoModelForCausalLM.from_pretrained(
"EleutherAI/gpt-neo-125m",
load_in_8bit=True,
device_map="auto",
)
trainer = SFTTrainer(
model,
train_dataset=dataset,
args=SFTConfig(),
peft_config=peft_config,
)
trainer.train()Using Flash Attention and Flash Attention 2
请注意,Flash Attention目前只在GPU上工作,并且需要在半精度模式下(使用适配器时,基础模型以半精度加载)。另外,这两个功能与量化等其他工具完全兼容。
Using Flash-Attention 1
对于Flash Attention 1,您可以使用BetterTransformer API,并强制API使用Flash Attention内核。首先,安装最新的optimum包:
pip install -U optimum一旦加载了您的模型,将 trainer.train() 调用包裹在 with torch.backends.cuda.sdp_kernel(enable_flash=True, enable_math=False, enable_mem_efficient=False): 上下文管理器中:
...
+ with torch.backends.cuda.sdp_kernel(enable_flash=True, enable_math=False, enable_mem_efficient=False):
trainer.train()请注意,您不能在任意数据集上使用 Flash Attention 1 来训练您的模型,因为如果使用 Flash Attention 内核,torch.scaled_dot_product_attention 不支持使用填充令牌进行训练。因此,您只能在设置 packing=True 的情况下使用该功能。如果您的数据集包含填充令牌,请考虑切换到 Flash Attention 2 集成。
Using Flash Attention-2
要使用 Flash Attention 2,首先安装最新的 flash-attn 包:
pip install -U flash-attn并在调用 from_pretrained 时添加 attn_implementation=”flash_attention_2”:
model = AutoModelForCausalLM.from_pretrained(
model_id,
load_in_4bit=True,
attn_implementation="flash_attention_2"
)如果您不使用量化,请确保您的模型以半精度加载,并将模型调度到支持的 GPU 设备上。加载模型后,您可以按原样训练它,或者在模型量化的情况下,附加适配器并在其上训练适配器。
与 Flash Attention 1 相比,该集成使得您的模型可以在包括填充令牌的任意数据集上进行训练。
Using model creation utility
我们包含了一个实用函数来创建您的模型。
trl.ModelConfig: https://huggingface.co/docs/trl/sft_trainer#trl.ModelConfig
HfArgumentParser: https://huggingface.co/docs/transformers/v4.45.1/en/internal/trainer_utils#transformers.HfArgumentParser
from trl import ModelConfig, SFTTrainer, get_kbit_device_map, get_peft_config, get_quantization_config
model_config = ModelConfig(
model_name_or_path="facebook/opt-350m"
attn_implementation=None, # or "flash_attention_2"
)
torch_dtype = (
model_config.torch_dtype
if model_config.torch_dtype in ["auto", None]
else getattr(torch, model_config.torch_dtype)
)
quantization_config = get_quantization_config(model_config)
model_kwargs = dict(
revision=model_config.model_revision,
trust_remote_code=model_config.trust_remote_code,
attn_implementation=model_config.attn_implementation,
torch_dtype=torch_dtype,
use_cache=False if training_args.gradient_checkpointing else True,
device_map=get_kbit_device_map() if quantization_config is not None else None,
quantization_config=quantization_config,
)
model = AutoModelForCausalLM.from_pretrained(model_config.model_name_or_path, **model_kwargs)
trainer = SFTTrainer(
...,
model=model_config.model_name_or_path,
peft_config=get_peft_config(model_config),
)使用NEFTune增强模型的性能
NEFTune是一种提升聊天模型性能的技术,由Jain等人的论文《NEFTune: Noisy Embeddings Improve Instruction Finetuning》提出。该技术包括在训练过程中向嵌入向量添加噪声。根据论文摘要:
Standard finetuning of LLaMA-2-7B using Alpaca achieves 29.79% on AlpacaEval, which rises to 64.69% using noisy embeddings. NEFTune also improves over strong baselines on modern instruction datasets. Models trained with Evol-Instruct see a 10% improvement, with ShareGPT an 8% improvement, and with OpenPlatypus an 8% improvement. Even powerful models further refined with RLHF such as LLaMA-2-Chat benefit from additional training with NEFTune.
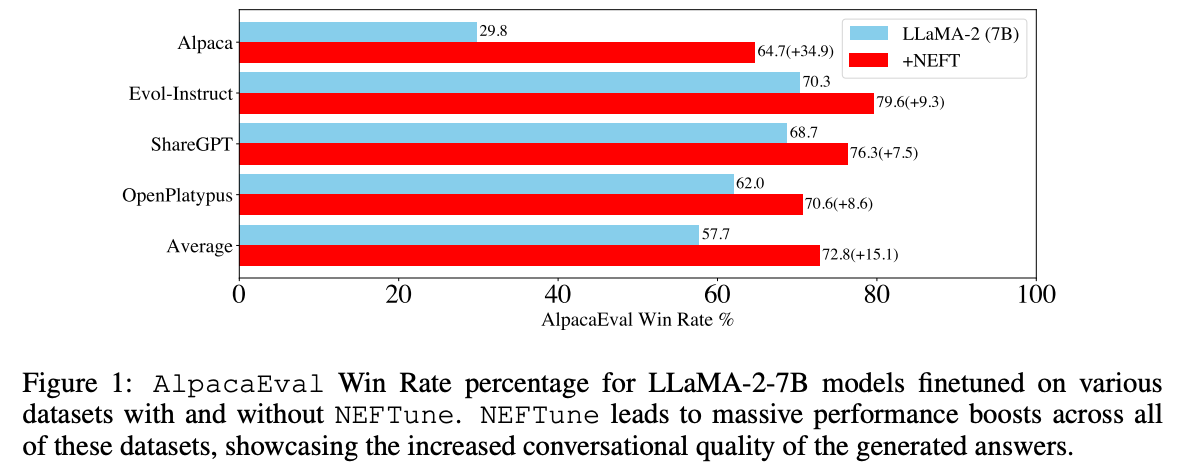
要在SFTTrainer中使用它,只需在创建您的SFTConfig实例时传递neftune_noise_alpha。请注意,为了避免任何意外行为,NEFTune在训练后会被禁用,以恢复嵌入层的原始行为。
from datasets import load_dataset
from trl import SFTConfig, SFTTrainer
dataset = load_dataset("stanfordnlp/imdb", split="train")
sft_config = SFTConfig(
neftune_noise_alpha=5,
)
trainer = SFTTrainer(
"facebook/opt-350m",
train_dataset=dataset,
args=sft_config,
)
trainer.train()我们已经通过在OpenAssistant数据集上训练mistralai/Mistral-7B-v0.1来测试了NEFTune,并验证了使用NEFTune在MT Bench上实现了约25%的性能提升。
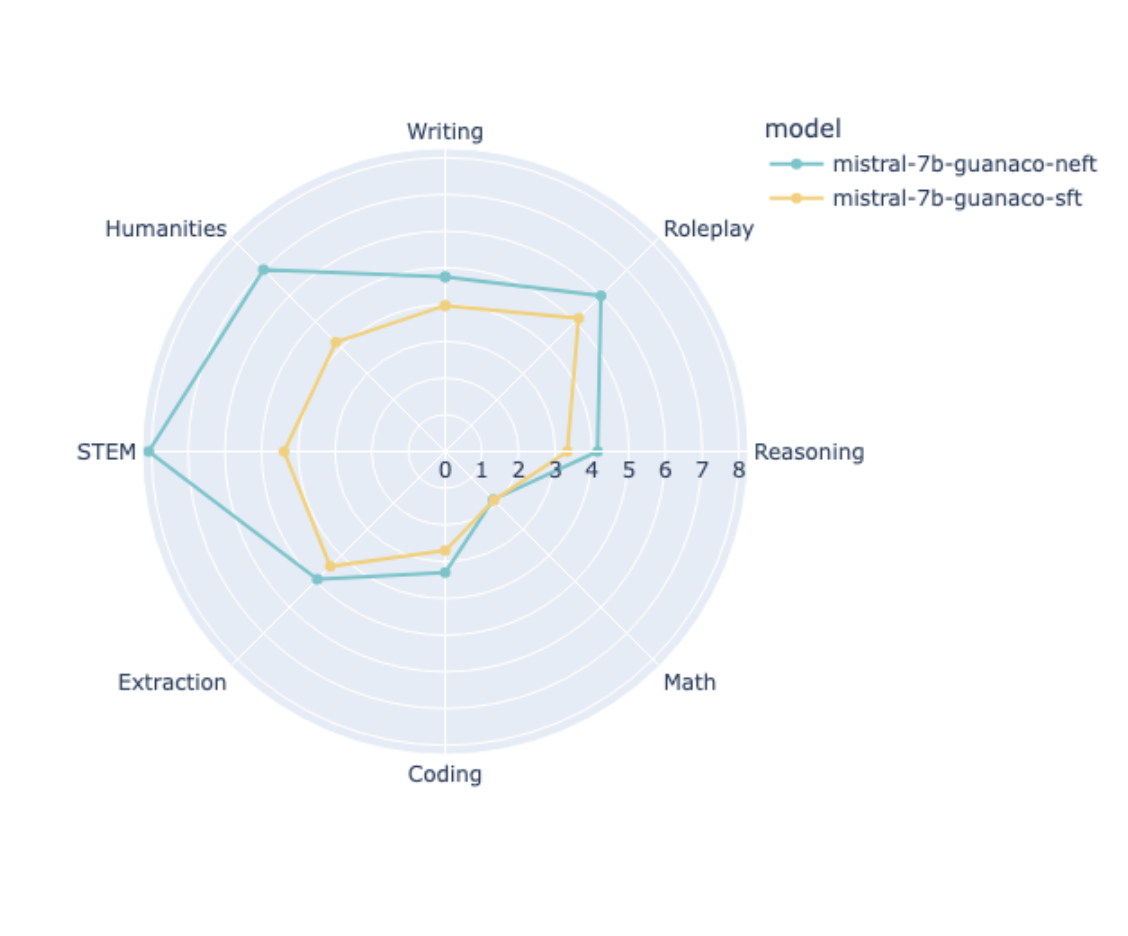
然而,请注意,性能提升的程度取决于数据集,特别是,在像UltraChat这样的合成数据集上应用NEFTune通常会产生较小的增益。
Accelerate fine-tuning 2x using unsloth
您可以使用与SFTTrainer完全兼容的unsloth库来进一步加速QLoRA / LoRA(速度提升2倍,内存减少60%)。目前unsloth仅支持Llama(Yi, TinyLlama, Qwen, Deepseek等)和Mistral架构。
首先根据官方文档安装unsloth。安装完成后,您可以通过非常简单的方式将unsloth融入您的工作流程中;不是加载AutoModelForCausalLM,您只需要按以下方式加载一个FastLanguageModel:
import torch
from trl import SFTConfig, SFTTrainer
from unsloth import FastLanguageModel
max_seq_length = 2048 # Supports automatic RoPE Scaling, so choose any number
# Load model
model, tokenizer = FastLanguageModel.from_pretrained(
model_name="unsloth/mistral-7b",
max_seq_length=max_seq_length,
dtype=None, # None for auto detection. Float16 for Tesla T4, V100, Bfloat16 for Ampere+
load_in_4bit=True, # Use 4bit quantization to reduce memory usage. Can be False
# token = "hf_...", # use one if using gated models like meta-llama/Llama-2-7b-hf
)
# Do model patching and add fast LoRA weights
model = FastLanguageModel.get_peft_model(
model,
r=16,
target_modules=[
"q_proj",
"k_proj",
"v_proj",
"o_proj",
"gate_proj",
"up_proj",
"down_proj",
],
lora_alpha=16,
lora_dropout=0, # Dropout = 0 is currently optimized
bias="none", # Bias = "none" is currently optimized
use_gradient_checkpointing=True,
random_state=3407,
)
args = SFTConfig(
output_dir="./output",
max_seq_length=max_seq_length,
dataset_text_field="text",
)
trainer = SFTTrainer(
model=model,
args=args,
train_dataset=dataset,
)
trainer.train()保存的模型与Hugging Face的transformers库完全兼容。在他们的官方仓库中了解更多关于unsloth的信息。
Liger-Kernel:在多GPU训练中提高20%的吞吐量并减少60%的内存使用
Liger Kernel是一系列专门为大型语言模型(LLM)训练设计的Triton内核。它能够有效地在多GPU训练中提高20%的吞吐量,并减少60%的内存使用。这样,我们可以在以下基准测试中所描述的,将上下文长度扩展4倍。他们已经实现了与Hugging Face兼容的RMSNorm、RoPE、SwiGLU、CrossEntropy、FusedLinearCrossEntropy等内核,并且还会有更多内核加入。这个内核可以开箱即用地与Flash Attention、PyTorch FSDP和Microsoft DeepSpeed配合使用。
凭借大幅度的内存减少,您有可能关闭cpu_offloading或梯度检查点(gradient checkpointing)来进一步提升性能。
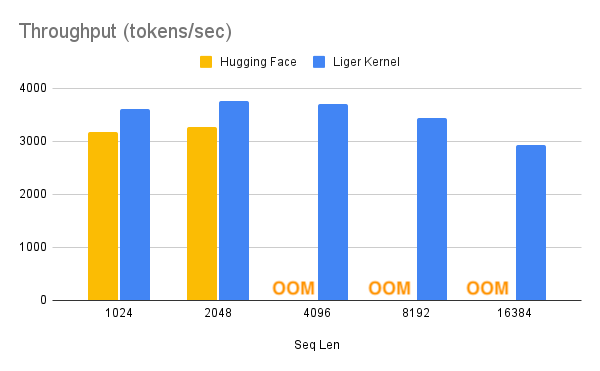
- 要在SFTTrainer中使用Liger-Kernel,首先进行安装,操作如下:
pip install liger-kernel- 安装完成后,在SFTConfig中设置use_liger。不需要进行其他更改!
config = SFTConfig(
use_liger=True
)想要了解更多关于Liger-Kernel的信息,请访问它们的官方仓库。
最佳实践
在训练模型时,请注意以下最佳实践:
- SFTTrainer默认情况下总是将序列填充到SFTTrainer的max_seq_length参数指定的长度。如果没有传递该参数,训练器将从tokenizer中获取该值。一些tokenizer不提供默认值,因此会有一个检查来获取2048和该值之间的最小值。在训练前请确保检查这一点。
- 对于在8位模式下训练适配器,您可能需要调整PEFT中的prepare_model_for_kbit_training方法的参数,因此我们建议用户使用prepare_in_int8_kwargs字段,或者在外部创建PeftModel并传递给它。
- 为了更高效地使用适配器进行训练,您可以将基础模型以8位模式加载。只需在创建SFTTrainer时添加load_in_8bit参数,或者在外部以8位模式创建一个基础模型并传递给它即可。
- 如果您在训练器外部创建模型,请确保不要向训练器传递任何与from_pretrained()方法相关的额外关键字参数。
Multi-GPU Training
训练器(以及SFTTrainer)支持多GPU训练。如果您使用python script.py运行您的脚本,它将默认使用DP(Data Parallel)作为策略,这可能比预期的要慢。要使用DDP(Distributed Data Parallel,通常建议使用,更多信息请参见这里),您必须使用python -m torch.distributed.launch script.py或accelerate launch script.py来启动脚本。为了使DDP正常工作,您还必须检查以下内容:
- 如果您正在使用gradient_checkpointing,请在TrainingArguments中添加以下内容:
gradient_checkpointing_kwargs={'use_reentrant':False}(更多信息请点击这里) - 确保模型被放置在正确的设备上:
from accelerate import PartialState
device_string = PartialState().process_index
model = AutoModelForCausalLM.from_pretrained(
...
device_map={'':device_string}
)GPTQ Conversion
在完成训练后,您可能会在使用GPTQ量化时遇到一些问题。将gradient_accumulation_steps降低到4可以在量化过程转换为GPTQ格式时解决大多数问题。
SFTTrainer
SFTTrainer: https://huggingface.co/docs/trl/sft_trainer#trl.SFTTrainer
SFTConfig
SFTConfig: https://huggingface.co/docs/trl/sft_trainer#trl.SFTConfig
Datasets
Datasets: https://huggingface.co/docs/trl/sft_trainer#datasets
结语
第一百八十九篇博文写完,开心!!!!
今天,也是充满希望的一天。



