前言
在本节中,我们将更深入地了解🤗 Transformers中的分词器的功能。到目前为止,我们只使用它们来分词输入或将ID解码回文本,但分词器——特别是那些由🤗 Tokenizers库支持的分词器——可以做更多的事情。为了说明这些附加功能,我们将探讨如何重现我们在第1章中首次遇到的token-classification(我们称之为ner)和question-answering管道的结果。
在接下来的讨论中,我们经常会区分“慢”和“快”分词器。慢分词器是写在🤗 Transformers库内的Python代码,而快分词器则是由🤗 Tokenizers提供的,它们是用Rust编写的。如果你还记得第5章中的表格,它报告了一个快分词器和一个慢分词器对Drug Review Dataset进行分词所需的时间,你应该能明白为什么我们称它们为快和慢:
| Fast tokenizer | Slow tokenizer | |
|---|---|---|
| batched=True | 10.8s | 4min41s |
| batched=False | 59.2s | 5min3s |
⚠️ 当对单个句子进行分词时,你并不总是能看到同一分词器的慢版本和快版本之间的速度差异。实际上,快版本可能实际上更慢!只有当同时并行地对大量文本进行分词时,你才能清楚地看到差异。
src link: https://huggingface.co/learn/nlp-course/chapter6/3
Operating System: Ubuntu 22.04.4 LTS
参考文档
批量编码
分词器的输出不是一个简单的Python字典;我们实际上得到的是一个特殊的BatchEncoding对象。它是字典的子类(这就是为什么我们之前能够没有任何问题地索引到那个结果),但具有主要用于快分词器的附加方法。
除了它们的并行化能力外,快分词器的关键功能是它们始终跟踪最终令牌来自的原始文本范围——我们称之为偏移量映射的功能。这反过来又解锁了将每个单词映射到它生成的令牌,或者将原始文本的每个字符映射到它所在的令牌,反之亦然等功能。
让我们来看一个例子:
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
example = "My name is Sylvain and I work at Hugging Face in Brooklyn."
encoding = tokenizer(example)
print(type(encoding))如前所述,我们在分词器的输出中得到了一个BatchEncoding对象:
<class 'transformers.tokenization_utils_base.BatchEncoding'>由于AutoTokenizer类默认选择一个快分词器,我们可以使用这个BatchEncoding对象提供的附加方法。我们有两种方法来检查我们的分词器是快还是慢。我们可以检查分词器的is_fast属性:
tokenizer.is_fastTrue或者检查我们编码的相同属性:
encoding.is_fastTrue让我们看看快速分词器能让我们做什么。首先,我们可以在不将ID转换回令牌的情况下访问令牌。
encoding.tokens()['[CLS]', 'My', 'name', 'is', 'S', '##yl', '##va', '##in', 'and', 'I', 'work', 'at', 'Hu', '##gging', 'Face', 'in',
'Brooklyn', '.', '[SEP]']在这种情况下,索引为5的令牌是##yl,它是原始句子中单词“Sylvain”的一部分。我们还可以使用word_ids()方法来获取每个令牌来自的单词的索引。
encoding.word_ids()[None, 0, 1, 2, 3, 3, 3, 3, 4, 5, 6, 7, 8, 8, 9, 10, 11, 12, None]我们可以看到,分词器的特殊令牌[CLS]和[SEP]被映射为None,然后每个令牌被映射到它源自的单词。这对于确定一个令牌是否位于单词的开头或者两个令牌是否在同一个单词中特别有用。我们可以依赖于##前缀来实现这一点,但它只适用于类似BERT的分词器;这种方法适用于任何类型的快速分词器。在下一章中,我们将看到如何利用这种能力,将我们为每个单词分配的标签正确地应用于命名实体识别(NER)和词性标注(POS)等任务中的令牌。我们还可以使用它在蒙版语言建模中屏蔽来自同一单词的所有令牌(一种称为整词蒙版的技术)。
单词的概念很复杂。例如,“I’ll”(“I will”的缩写)算作一个单词还是两个单词?实际上,这取决于分词器和它应用的预分词操作。有些分词器只是按空格分割,所以它们会将其视为一个单词。其他的则使用标点符号和空格,因此会将其视为两个单词。
✏️ 尝试一下!从bert-base-cased和roberta-base检查点创建一个分词器,并用它们对”81s”进行分词。你观察到了什么?单词ID是什么?
同样,有一个sentence_ids()方法,我们可以用它将令牌映射到它来自的句子(尽管在这种情况下,分词器返回的token_type_ids可以给我们相同的信息)。
最后,我们可以通过word_to_chars()或token_to_chars()以及char_to_word()或char_to_token()方法,将任何单词或令牌映射到原始文本中的字符,反之亦然。例如,word_ids()方法告诉我们##yl是索引为3的单词的一部分,但它是句子中的哪个单词呢?我们可以这样找到答案:
start, end = encoding.word_to_chars(3)
example[start:end]Sylvain正如我们之前提到的,这一切都是因为快速分词器跟踪每个令牌来自的文本跨度,这个信息存储在一个偏移量列表中。为了说明它们的使用方法,接下来我们将向您展示如何手动复制令牌分类管道的结果。
试一试!创建你自己的示例文本,看看你是否能理解哪些令牌与单词ID相关联,以及如何提取单个单词的字符跨度。作为额外的挑战,尝试使用两个句子作为输入,看看句子ID对你是否有意义。
在令牌分类管道内部
在第一章中,我们第一次尝试使用🤗 Transformers的pipeline()函数应用命名实体识别(NER)——这项任务是要识别文本中哪些部分对应于如人名、地点或组织这样的实体。然后在第二章中,我们看到了一个管道如何将三个必要阶段组合在一起,以从原始文本中获得预测:分词、通过模型传递输入以及后处理。令牌分类管道中的前两个步骤与其他任何管道中的步骤相同,但后处理稍微复杂一些——让我们来看看是如何的!
使用管道获取基本结果
首先,让我们获取一个令牌分类管道,以便我们可以获得一些结果与手动进行比较。默认使用的模型是dbmdz/bert-large-cased-finetuned-conll03-english;它在句子上进行命名实体识别(NER):
from transformers import pipeline
token_classifier = pipeline("token-classification")
token_classifier("My name is Sylvain and I work at Hugging Face in Brooklyn.")[{'entity': 'I-PER', 'score': 0.9993828, 'index': 4, 'word': 'S', 'start': 11, 'end': 12},
{'entity': 'I-PER', 'score': 0.99815476, 'index': 5, 'word': '##yl', 'start': 12, 'end': 14},
{'entity': 'I-PER', 'score': 0.99590725, 'index': 6, 'word': '##va', 'start': 14, 'end': 16},
{'entity': 'I-PER', 'score': 0.9992327, 'index': 7, 'word': '##in', 'start': 16, 'end': 18},
{'entity': 'I-ORG', 'score': 0.97389334, 'index': 12, 'word': 'Hu', 'start': 33, 'end': 35},
{'entity': 'I-ORG', 'score': 0.976115, 'index': 13, 'word': '##gging', 'start': 35, 'end': 40},
{'entity': 'I-ORG', 'score': 0.98879766, 'index': 14, 'word': 'Face', 'start': 41, 'end': 45},
{'entity': 'I-LOC', 'score': 0.99321055, 'index': 16, 'word': 'Brooklyn', 'start': 49, 'end': 57}]该模型正确地识别了由“Sylvain”生成的每个标记作为一个人,由“Hugging Face”生成的每个标记作为一个组织,以及标记“Brooklyn”作为一个地点。我们还可以要求管道将对应于同一实体的标记组合在一起。
from transformers import pipeline
token_classifier = pipeline("token-classification", aggregation_strategy="simple")
token_classifier("My name is Sylvain and I work at Hugging Face in Brooklyn.")[{'entity_group': 'PER', 'score': 0.9981694, 'word': 'Sylvain', 'start': 11, 'end': 18},
{'entity_group': 'ORG', 'score': 0.97960204, 'word': 'Hugging Face', 'start': 33, 'end': 45},
{'entity_group': 'LOC', 'score': 0.99321055, 'word': 'Brooklyn', 'start': 49, 'end': 57}]选定的聚合策略将改变为每个分组实体计算的分数。使用“simple”策略时,分数仅仅是给定实体中每个标记分数的平均值:例如,“Sylvain”的分数是我们在前一个示例中看到的标记 S, ##yl, ##va 和 ##in 的分数的平均值。其他可用的策略包括:
- “first”,其中每个实体的分数是该实体第一个标记的分数(所以对于“Sylvain”,它将是 0.993828,即标记 S 的分数)
- “max”,其中每个实体的分数是该实体标记中的最大分数(所以对于“Hugging Face”,它将是 0.98879766,即“Face”的分数)
- “average”,其中每个实体的分数是该实体组成单词的分数的平均值(所以对于“Sylvain”,与“simple”策略没有区别,但“Hugging Face”的分数将是 0.9819,即“Hugging”的分数 0.975 和“Face”的分数 0.98879 的平均值)
现在让我们看看如何在不使用 pipeline() 函数的情况下获得这些结果!
从输入到预测
首先,我们需要对输入进行标记化处理,并将其传递给模型。这个过程与第2章中的方法完全相同;我们使用AutoXxx类实例化标记器和模型,然后在我们的示例中使用它们:
from transformers import AutoTokenizer, AutoModelForTokenClassification
model_checkpoint = "dbmdz/bert-large-cased-finetuned-conll03-english"
tokenizer = AutoTokenizer.from_pretrained(model_checkpoint)
model = AutoModelForTokenClassification.from_pretrained(model_checkpoint)
example = "My name is Sylvain and I work at Hugging Face in Brooklyn."
inputs = tokenizer(example, return_tensors="pt")
outputs = model(**inputs)由于我们在这里使用了AutoModelForTokenClassification,因此输入序列中的每个令牌都会得到一组 logits。
print(inputs["input_ids"].shape)
print(outputs.logits.shape)torch.Size([1, 19])
torch.Size([1, 19, 9])我们有一个包含1个序列的批次,该序列有19个令牌,而模型有9个不同的标签,因此模型的输出形状为1 x 19 x 9。与文本分类管道类似,我们使用softmax函数将那些logits转换为概率,并取argmax以获得预测(请注意,我们可以对logits取argmax,因为softmax不会改变顺序)。
import torch
probabilities = torch.nn.functional.softmax(outputs.logits, dim=-1)[0].tolist()
predictions = outputs.logits.argmax(dim=-1)[0].tolist()
print(predictions)[0, 0, 0, 0, 4, 4, 4, 4, 0, 0, 0, 0, 6, 6, 6, 0, 8, 0, 0]模型的model.config.id2label属性包含了索引到标签的映射,我们可以使用它来理解预测结果。
model.config.id2label{0: 'O',
1: 'B-MISC',
2: 'I-MISC',
3: 'B-PER',
4: 'I-PER',
5: 'B-ORG',
6: 'I-ORG',
7: 'B-LOC',
8: 'I-LOC'}正如我们之前所看到的,有9个标签:O是那些不在任何命名实体中的令牌的标签(它代表“外部”),然后每种实体类型都有两个标签(杂项、人、组织和地点)。标签B-XXX表示令牌位于实体XXX的开始,标签I-XXX表示令牌位于实体XXX内部。例如,在当前的例子中,我们预计我们的模型会将令牌S分类为B-PER(人实体的开始)并将令牌##yl、##va和##in分类为I-PER(人实体内部)。
你可能会认为在这个例子中模型犯了错误,因为它将这四个令牌都标记为I-PER,但这并不完全正确。实际上,B-和I-标签有两种格式:IOB1和IOB2。我们介绍的是IOB2格式(如下面的粉色部分),而在IOB1格式(如下面的蓝色部分)中,以B-开头的标签仅用于分隔两个相同类型的相邻实体。我们使用的模型是在使用该格式的数据集上进行微调的,这就是为什么它将S令牌分配给I-PER标签的原因。
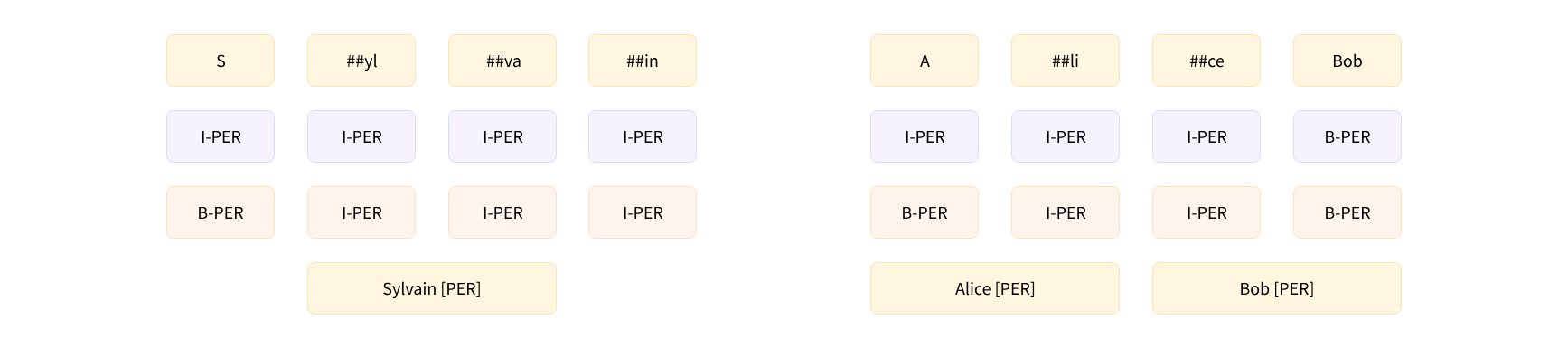
凭借这个映射,我们准备好重新生成(几乎全部)第一条管道的结果了——我们可以直接获取每个未被归类为O的标记的分数和标签:
results = []
tokens = inputs.tokens()
for idx, pred in enumerate(predictions):
label = model.config.id2label[pred]
if label != "O":
results.append(
{"entity": label, "score": probabilities[idx][pred], "word": tokens[idx]}
)
print(results)[{'entity': 'I-PER', 'score': 0.9993828, 'index': 4, 'word': 'S'},
{'entity': 'I-PER', 'score': 0.99815476, 'index': 5, 'word': '##yl'},
{'entity': 'I-PER', 'score': 0.99590725, 'index': 6, 'word': '##va'},
{'entity': 'I-PER', 'score': 0.9992327, 'index': 7, 'word': '##in'},
{'entity': 'I-ORG', 'score': 0.97389334, 'index': 12, 'word': 'Hu'},
{'entity': 'I-ORG', 'score': 0.976115, 'index': 13, 'word': '##gging'},
{'entity': 'I-ORG', 'score': 0.98879766, 'index': 14, 'word': 'Face'},
{'entity': 'I-LOC', 'score': 0.99321055, 'index': 16, 'word': 'Brooklyn'}]这与我们之前的内容非常相似,只有一个例外:管道还向我们提供了原始句子中每个实体开始和结束的信息。这就是我们的偏移量映射将发挥作用的地方。为了获得偏移量,我们只需在将分词器应用于输入时设置 return_offsets_mapping=True:
inputs_with_offsets = tokenizer(example, return_offsets_mapping=True)
inputs_with_offsets["offset_mapping"][(0, 0), (0, 2), (3, 7), (8, 10), (11, 12), (12, 14), (14, 16), (16, 18), (19, 22), (23, 24), (25, 29), (30, 32),
(33, 35), (35, 40), (41, 45), (46, 48), (49, 57), (57, 58), (0, 0)]每个元组都是与每个标记对应的文本跨度,其中 (0, 0) 是为特殊标记保留的。我们之前看到,索引为5的标记是 ##yl,在这里它的偏移量是 (12, 14)。如果我们抓取示例中的相应切片:
example[12:14]我们得到了没有 ## 的正确文本跨度。
yl利用这一点,我们现在可以完成之前的结果:
results = []
inputs_with_offsets = tokenizer(example, return_offsets_mapping=True)
tokens = inputs_with_offsets.tokens()
offsets = inputs_with_offsets["offset_mapping"]
for idx, pred in enumerate(predictions):
label = model.config.id2label[pred]
if label != "O":
start, end = offsets[idx]
results.append(
{
"entity": label,
"score": probabilities[idx][pred],
"word": tokens[idx],
"start": start,
"end": end,
}
)
print(results)[{'entity': 'I-PER', 'score': 0.9993828, 'index': 4, 'word': 'S', 'start': 11, 'end': 12},
{'entity': 'I-PER', 'score': 0.99815476, 'index': 5, 'word': '##yl', 'start': 12, 'end': 14},
{'entity': 'I-PER', 'score': 0.99590725, 'index': 6, 'word': '##va', 'start': 14, 'end': 16},
{'entity': 'I-PER', 'score': 0.9992327, 'index': 7, 'word': '##in', 'start': 16, 'end': 18},
{'entity': 'I-ORG', 'score': 0.97389334, 'index': 12, 'word': 'Hu', 'start': 33, 'end': 35},
{'entity': 'I-ORG', 'score': 0.976115, 'index': 13, 'word': '##gging', 'start': 35, 'end': 40},
{'entity': 'I-ORG', 'score': 0.98879766, 'index': 14, 'word': 'Face', 'start': 41, 'end': 45},
{'entity': 'I-LOC', 'score': 0.99321055, 'index': 16, 'word': 'Brooklyn', 'start': 49, 'end': 57}]这与我们从第一条管道得到的结果相同!
分组实体
使用偏移量来确定每个实体的起始和结束键是方便的,但这一信息并非绝对必要。然而,当我们想要将实体分组时,偏移量可以为我们节省大量复杂的代码。例如,如果我们想要将标记 Hu, ##gging 和 Face 分组在一起,我们可以制定特殊规则,规定前两个标记应该连接在一起同时去掉 ##,而 Face 应该添加空格,因为它不以 ## 开头——但这只适用于这种特定类型的标记器。对于 SentencePiece 或 Byte-Pair-Encoding 标记器(将在本章后面讨论),我们必须编写另一套规则。
有了偏移量,所有这些自定义代码都不再需要:我们只需取原始文本中从第一个标记开始到最后一个标记结束的跨度。所以,在标记 Hu, ##gging 和 Face 的情况下,我们应该从第 33 个字符(Hu 的开始)开始,在第 45 个字符(Face 的结束)之前结束:
example[33:45]Hugging Face为了编写在分组实体时对预测进行后处理的代码,我们将把连续且标记为 I-XXX 的实体分组在一起,除了第一个,它可以标记为 B-XXX 或 I-XXX(所以,当我们遇到 O、新的实体类型或告诉我们同一类型实体开始的 B-XXX 时,我们停止分组实体):
import numpy as np
results = []
inputs_with_offsets = tokenizer(example, return_offsets_mapping=True)
tokens = inputs_with_offsets.tokens()
offsets = inputs_with_offsets["offset_mapping"]
idx = 0
while idx < len(predictions):
pred = predictions[idx]
label = model.config.id2label[pred]
if label != "O":
# Remove the B- or I-
label = label[2:]
start, _ = offsets[idx]
# Grab all the tokens labeled with I-label
all_scores = []
while (
idx < len(predictions)
and model.config.id2label[predictions[idx]] == f"I-{label}"
):
all_scores.append(probabilities[idx][pred])
_, end = offsets[idx]
idx += 1
# The score is the mean of all the scores of the tokens in that grouped entity
score = np.mean(all_scores).item()
word = example[start:end]
results.append(
{
"entity_group": label,
"score": score,
"word": word,
"start": start,
"end": end,
}
)
idx += 1
print(results)我们得到了与第二个管道相同的结果!
[{'entity_group': 'PER', 'score': 0.9981694, 'word': 'Sylvain', 'start': 11, 'end': 18},
{'entity_group': 'ORG', 'score': 0.97960204, 'word': 'Hugging Face', 'start': 33, 'end': 45},
{'entity_group': 'LOC', 'score': 0.99321055, 'word': 'Brooklyn', 'start': 49, 'end': 57}]偏移量极其有用的另一个任务是问答。在下一节中,我们将深入探讨这个管道,同时也能让我们一瞥 🤗 Transformers 库中标记器的最后一个特性:在将输入截断到给定长度时处理溢出的标记。
结语
第二百五十二篇博文写完,开心!!!!
今天,也是充满希望的一天。



